

Never Miss a Beat: Get a snapshot of the issues affecting the IT industry straight to your inbox.
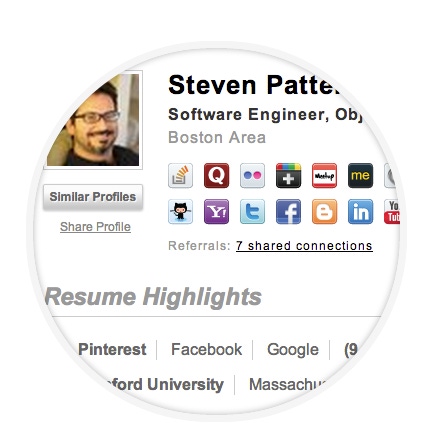
What do your public social network posts say about you? TalentBin by Monster aggregates them into a database for hiring managers -- whether you're looking for a job or not.
3 Min Read

Hadoop Jobs: 9 Ways To Get Hired
Hadoop Jobs: 9 Ways To Get Hired (Click image for larger view and slideshow.)
It's no secret that recruiters and hiring managers vet potential candidates through their social networks. But a new tool from job search site Monster uses your public posts in a new way: To match you -- whether you're job searching or not -- with open positions based on your social media activity.
TalentBin by Monster crawls social networks such as Facebook, Twitter, LinkedIn, Stack Overflow, GitHub, Blogger, YouTube, and others for your most recent professional-related public activity, and aggregates it into one profile. This information might include code you shared on GitHub, industry events you RSVP'd to on Facebook or Meetup, or even patents you've filed, for example.
Recruiters can then search TalentBin's database -- which already includes more than 115 million people -- for candidates based on the social activity it surfaces. TalentBin also integrates native messaging with various social networks, which lets recruiters email you -- if you provided that information on a social network -- or message you through a site, such as a Twitter direct message or Facebook message.
[Do you deserve a bigger paycheck? Read IT Salary: 10 Ways To Get A Raise.]
"Much of social recruiting has been about putting together social profiles and presenting it to the world," said Matt Mund, senior VP of product management at Monster, in an interview. "But recruiters don't want someone who's the best at marketing themselves, they want the best candidates -- and sometimes those are the people who aren't even looking for jobs."
TalentBin's technology uses an algorithm that separates personal posts such as photos of your family or restaurants you visited from information that it deems professional, Mund said.
"We're very sensitive to privacy and we only use public data. If you ever wanted to Google yourself, you'd see what's out there for people to find. All TalentBin does is facilitate this by pulling in relevant content through a professional filter," he said.
TalentBin's database is focused only on high-tech candidates right now, Mund said, since they tend to be further ahead of the curve on adopting new technology and because the demand for tech talent is high. TalentBin will eventually expand to other sectors such as engineering and healthcare, he said.
According to a report by Jobvite, 94% of recruiters use or plan to use social media in their recruitment efforts while 78% said they have made a hire through social media. As these numbers grow, Mund said it's important for people, whether they're active or passive candidates, to consider how their social media presence could impact them professionally -- not only negatively, but positively, too.
"If you're attending an iOS meet-up or a technology conference, post it publicly on Facebook or in some other social context. To be found, you have to participate in social media. You need to be out there talking about development environments and coding and which language is the best one for a project," he said. "The more that you do, the better your chances are of being found."
Of course, if you don't want to be found, TalentBin offers you an option to opt-out.
Our InformationWeek Elite 100 issue -- our 26th ranking of technology innovators -- shines a spotlight on businesses that are succeeding because of their digital strategies. We take a close at look at the top five companies in this year's ranking and the eight winners of our Business Innovation awards, and we offer 20 great ideas that you can use in your company. We also provide a ranked list of our Elite 100 innovators. Read our InformationWeek Elite 100 issue today.
About the Author(s)
You May Also Like
More Insights
Editor's Choice





May 2, 2024
While there are plentiful options in cyber resiliency and business continuity tools and platforms, there isn’t one that can knock out everything from sudden cloud outages to prolonged ransomware attacks in a single punch. What can you do to keep the company on its feet no matter what is thrown at it? Find out in this new virtual event.
Reserve Your Seat Now