

Never Miss a Beat: Get a snapshot of the issues affecting the IT industry straight to your inbox.
Teradata QueryGrid: Beyond Enterprise Data Warehouse
Teradata adds unified fabric access to myriad databases and Hadoop, triggering multiple analysis engines with a single query. Say goodbye to yesterday's enterprise data warehouse ideas.
4 Min Read
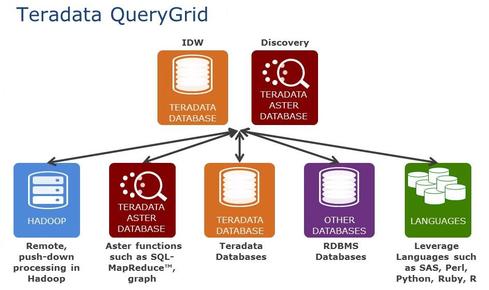
Teradata, the enterprise data warehouse (EDW) company, announced a QueryGrid data-access layer on Monday that can orchestrate multiple modes of analysis across multiple databases plus Hadoop. It's a next step toward Gartner's vision of a logical data warehouse and an acknowledgement that the notion of the EDW has fundamentally changed.
Teradata has already acknowledged the world beyond the EDW with its Unified Data Architecture, which incorporates the Teradata Aster database for data discovery and Hadoop for varied and voluminous data not well suited to relational database management systems (DBMS). The QueryGrid adds a single execution layer that orchestrates analyses across Teradata, Teradata's Asterdata DBMS, Oracle, Hadoop, and, in the future, other databases and platforms. The analysis options include SQL queries, as well as graph, MapReduce, R-based analytics, and other applications.
"Users don't care if information is sitting inside of a data warehouse or Hadoop, and enterprises don't want a lot of data movement or data duplication," said Chris Twogood, Teradata's vice president of product and services marketing. "The QueryGrid gives them a transparent way to optimize the power of different technologies within a logical data warehouse."
[Want more on the emergence of new analysis techniques? Read Merck Optimizes Manufacturing With Big Data Analytics.]
Offering two-way, Infiniband connectivity among data sources, the QueryGrid can execute sophisticated, multi-part analyses. After finding a segment of high-value customers in Teradata, for example, you could push that subset into Hadoop to explore their sentiments as revealed in Twitter and Facebook social comments. Spotting customers likely to churn -- based on negative sentiments -- you could bring that subset into Asterdata, where graph analysis could be used to spot the most influential customers. Voila: you have a list of high-value, well-connected customers that should be included in an anti-churn campaign.
"There are so many specialized engines, so we want to be able to leverage and integrate those while enabling users of the data warehouse to be able to invoke those techniques," Twogood said.
Teradata isn't the only vendor building what Gartner calls the logical data warehouse. Just last month, SAP introduced its Hana In-Memory Data Fabric for federated data access across sources. And since 2009, IBM has offered its DB2 Information Integrator for federated access to multiple data sources. But where these tools are SQL centric, Teradata's differentiator is broader access to a variety of analysis engines.
With an eye toward heterogeneity, Teradata also introduced Teradata 15 on Monday. This DBMS update adds support for JSON data and goes beyond SQL to invoke applications written in Python, Perl, Ruby, R, and other languages to come.
"This gives you the architectural flexibility to separate the presentation layer and the data-analytics layer," said Alan Greenspan, a product marketing manager at Teradata. "Instead of forcing developers to turn to the data warehouse group to do everything in SQL, they can write their own code and execute it in parallel within the database." The approach avoids data movement, data processing on application servers, and other workarounds between web developers and data-management teams. Greenspan said.
Teradata also announced on Monday an upgrade of its flagship hardware platform. The upgrade offers eight times more memory and three times more solid-state drives per rack than what is delivered in the 6700 series introduced 18 months ago. With 512 gigabytes of memory now available per compute node, Teredata's Intelligent Memory feature can now hold more high-demand data in-memory for lightning-fast, RAM-access-speed analysis.
Introduced in 2013, Teradata Intelligent Memory automatically moves high-demand data to the fastest storage choices available while moving low-demand data to the lowest-cost storage options like high-capacity disk drives. It was a response to SAP's Hana in-memory platform and a preemptive move ahead of the Microsoft and Oracle in-memory options being introduced this year.
The biggest news here is clearly the QueryGrid. After years of preaching that everything should go in the enterprise data warehouse, Teradata is acknowledging and embracing a world in which the EDW doesn't have to be the center of analysis.
What do Uber, Bank of America, and Walgreens have to do with your mobile app strategy? Find out in the new Maximizing Mobility issue of InformationWeek Tech Digest.
About the Author(s)
You May Also Like
More Insights
Webinars
Editor's Choice





May 2, 2024
While there are plentiful options in cyber resiliency and business continuity tools and platforms, there isn’t one that can knock out everything from sudden cloud outages to prolonged ransomware attacks in a single punch. What can you do to keep the company on its feet no matter what is thrown at it? Find out in this new virtual event.
Reserve Your Seat Now