

Never Miss a Beat: Get a snapshot of the issues affecting the IT industry straight to your inbox.
MemSQL, VoltDB present in-memory databases as alternatives to a menagerie of "science projects" used in real-time big data apps. Is SQL simpler?
4 Min Read
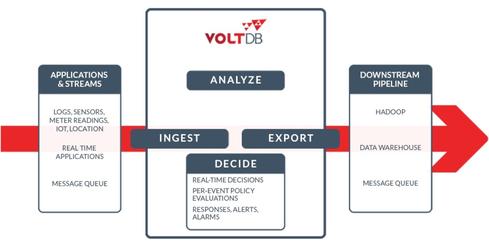
VoltDB expects to displace Spark Streaming, Storm, and other tools.
Why use a battery of "complicated" and "immature" tools like Kafka, Zookeeper, and NoSQL databases to support low-latency big data applications when you can use a durable, consistent, SQL-compliant in-memory database?
This is the question NewSQL in-memory database vendors MemSQL and VoltDB are posing to big-data developers who are trying to build real-time applications. MemSQL this week announced a two-way, high-performance MemSQL Spark Connector designed to complement the fast-growing Apache Spark in-memory analytics platform.
"There's a lot of excitement about Spark, but many data scientists struggle with complexity and the high degree of expertise to work with related data pipelines," said Erik Frenkiel, CEO and cofounder of MemSQL, in a phone interview with InformationWeek. "As a database, MemSQL offers durability and transaction support, so it can simplify those real-time data pipelines, providing the ability to ingest data and query the system through a SQL interface."
[ Want more on this topic? Read 10 In-Memory Database Options Power Speedy Performance. ]
MemSQL sees two key use-cases for its connector, and in both cases the idea is operationalizing the Spark data-exploration and data-analysis platform. One use-case is taking the models developed in Spark and pushing them into MemSQL, a persistent, durable, and highly available database that can run enterprise applications, while also propagating the results of Spark-developed models at data-driven decision points.
A conventional, non-in-memory database could serve in this same role, ensuring snapshots, replication, and high-availability. But if you're tapping Spark for in-memory speed, chances are you're interested in performance and would not want to introduce disk-based write-and-retrieve bottlenecks elsewhere in a data-driven application.
A second use-case is stream or event processing where Spark ingests a real-time event feed, such as interactions on a social site or an e-commerce site, parses, and transforms that data into a SQL-query-friendly format, and then hands the results off to MemSQL. The database makes the events of interest -- likes or favorites on a social site or purchases on the e-commerce site -- SQL-accessible to applications and end-users.
MemSQL says its Spark connector is multi-threaded and highly parallelized to sustain low-latency performance. MemSQL also has connector to Hadoop, announced late last year, so the database can harness that high-scale platform as either a source of data or a final destination for results. But Hadoop still has a reputation as a batchy, complicated world that's not suited to real-time apps, despite the introduction of YARN and talk of low-latency engines running on top of it.
Hitting on some of these same real-time themes, VoltDB late last month announced a 5.0 release aimed at supporting a variety of streaming-data and Internet-of-things-style applications. VoltDB presents itself as an alternative to Spark Streaming and other streaming options, including Apache Storm and the Lambda Architecture associated with developing streaming data pipelines alongside Hadoop. [Author's note: This article was corrected to reflect that VoltDB presents its DBMS as an alternative to Spark Streaming specifically, not the entire Spark framework.]
"We got started on this because Crashlytics gave a talk about an implementation of Lambda that used Zookeeper, Kafka, Storm, and Cassandra on the speed layer and HDFS, Cascading, Kafka, and Zookeeper on the batch layer," John Hugg, a software engineer at VoltDB told InformationWeek. "Instead of running all of these disparate systems, you can replace several of them with VoltDB."

VoltDB expects to displace Spark Streaming, Storm, and other tools.
Specifically, Hugg says VoltDB can replace the ingestion of Kafka, the data-agreement of Zookeeper, the state-management of Cassandra, and the distributed processing of Storm. To provide integration options toward this end, the VoltDB 5.0 release incorporates a battery of new big data infrastructure connectors, including Hadoop (specifically, HDFS Export), HTTP Export, Kafka Export, and RabbitMQ Export. It also provides a Kafka Loader and bulk-data-import options, including JDBC Loader, Hadoop OutputFormat, and HP Vertica UDx.
What MemSQL and VoltDB are both underscoring is an important limitation of platforms like Spark and Storm, which have captured lots of mindshare for their analysis capabilities, but have yet to be put into production widely as parts of applications and systems.
"[Databases] can directly respond to queries, but with Storm and Spark Streaming, the question is how do I query that data?" Hugg explains. "I can use those systems to process data, but how do you get answers?"
Do you want to master myriad tools to solve that problem, or do you want to use a fast, scalable in-memory database to handle multiple roles?
Dark Reading's new Must Reads is a compendium of our best recent coverage of vulnerability management. Learn how a design flaw in an older version of the SSL encryption protocol could be used for man-in-the-middle attacks, how the Mayhem botnet malware kit serves enterprising criminals, why it's time to raise the bar on static analysis, and more. Get the Must Reads: Vulnerability Management issue of Dark Reading today. (Free registration required.)
About the Author(s)
You May Also Like
More Insights
Editor's Choice





May 2, 2024
While there are plentiful options in cyber resiliency and business continuity tools and platforms, there isn’t one that can knock out everything from sudden cloud outages to prolonged ransomware attacks in a single punch. What can you do to keep the company on its feet no matter what is thrown at it? Find out in this new virtual event.
Reserve Your Seat Now