

Never Miss a Beat: Get a snapshot of the issues affecting the IT industry straight to your inbox.
With the release of its Distribution 5.0 management tool and other features, MapR is looking to make Hadoop easier to use and increase its popularity within the enterprise.
3 Min Read
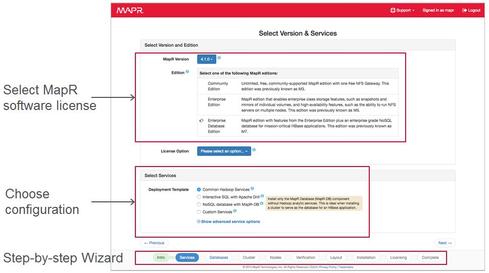
<p align="left">MapR's auto-provisioning template</p>

6 Causes Of Big Data Discrepancies
6 Causes Of Big Data Discrepancies (Click image for larger view and slideshow.)
MapR Technologies wants to make Hadoop faster for its users.
First, the company is releasing MapR Distribution 5.0 to speed real-time management of applications. Complementing this is the introduction of automated templates that can shrink the time it takes to deploy a Hadoop cluster from hours to minutes.
"(We're) looking at a trend. It's about helping companies become more agile. It is about data agility," explained Jack Norris, the chief marketing officer for MapR.
Companies that are handling thousands or millions of transactions online need a way to analyze and manage their applications in real time. These could be call centers, online shopping sites, financial service firms, and the like -- anything involving a high volume of transactions.
"Overall, this is going to help the organization compress data to the action cycle," Norris said.
Hadoop is usually used to collect, manage, and analyze large pools of big data. MapR's course is to add toolsets to link Hadoop to real-time operations, in effect tapping big data in real-time to sharpen decision-making.
MapR 5.0, which the company officially announced at the Hadoop Summit in San Jose, Calif., on Tuesday, June 9, will enable organizations to auto-synchronize storage, database, and search across the enterprise; improve its Real-time Data Transport framework to enable real-time search; allow rolling upgrades for applications in Hadoop clusters to complement platform-level upgrades; and improve data governance with auditing for all data access through Apache Drill 1.1, adjusting access privileges for specific analysts.
Concurrently, the MapR Auto-Provisioning Template is also being launched, making a big improvement in the deployment of Hadoop clusters.
Previously, "administrators deployed Hadoop on a node-by-node basis," Norris explained, which involved a lot of repetitive processes. Permissions and dependencies had to be set up just right on each node to avoid problems. Auto-provisioning simply automates that process so that Hadoop can be deployed across racks, with the flexibility to do complex provisions, he added. This can knock down a Hadoop deployment from hours to minutes.

MapR's data governance product.
The Auto-Provisioning Template is replete with control utilities. Common Hadoop services are all bundled together in a feature called "Data Lake." Interactive SQL with Apache Drill provides the data exploration component. NoSQL with MapR-DB provides the operational analytic portion. Auto-layout, rack awareness, and health checks automates distribution and monitoring for the systems administrator.
Hadoop is only 10-years-old. Yes, the child has grown. Over the years, developers have added tool sets and utilities to make Hadoop more commercially useful. But despite Hadoop's compelling utility, adoption has been slow.
"The big issue regarding Hadoop is education and knowledge transfer," Norris said. In January, MapR rolled out free online demos of Hadoop training tailored for administrators, developers, and data analysts. About 20,000 users are participating, Norris added.
[Read about big data in real life.]
Another MapR strategy to speed adoption is "making sure Hadoop integrates into existing environments," Norris continued. That means making sure MapR is not creating a separate environment for Hadoop. The solution needs "to be data centric, not Hadoop-centric," he said.
"We're going through one of the biggest re-platforming exercises in the data center," Norris said. As a result, MapR has to be in the center of enterprise computing. "We have to help organizations respond faster and more accurately to take advantage of changing business conditions," he said.
However, what companies such as MapR and even Salesforce are trying to do, is to make big data itself easier to use for the entire enterprise, not just data scientists or those with deep knowledge of the technology. If successful, these efforts could make big data a true, enterprise-wide technology that anyone can access and use.
About the Author(s)
You May Also Like
More Insights
Editor's Choice





May 2, 2024
While there are plentiful options in cyber resiliency and business continuity tools and platforms, there isn’t one that can knock out everything from sudden cloud outages to prolonged ransomware attacks in a single punch. What can you do to keep the company on its feet no matter what is thrown at it? Find out in this new virtual event.
Reserve Your Seat Now