

Never Miss a Beat: Get a snapshot of the issues affecting the IT industry straight to your inbox.
Databricks has a bold vision -- based on Apache Spark -- to become big data's epicenter of analysis. Executives Ion Stoica and Arsalan Tavakoli discuss the details and how Google Cloud Dataflow compares.
9 Min Read
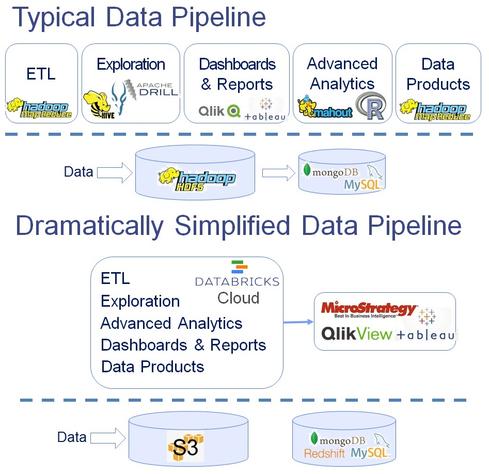
Databricks' depiction of Databricks Cloud replacing the many components of Hadoop used in today's big-data analyses.
If Databricks has its way, Apache Spark will become a pervasive choice for big data analysis, whether the work is done on the premises or in the cloud.
Spark was developed in UC Berkeley's AMPLab in 2009, and the project was committed to Apache open source in 2010. Databricks was set up as a commercial company with a mission to promote Spark and ensure a great user experience and support.
Figure 1:
Ion Stoica, a UC Berkeley professor since 2000, took leave to serve as CEO of Databricks. In this interview with InformationWeek he's joined by Arsalan Tavakoli, a McKinsey & Co. and UC Berkeley PhD program veteran, who leads Databricks' business development.
[Want more on Spark's potential impact? Read Will Spark, Google Dataflow Steal Hadoop's Thunder?]
What are Databricks' ambitions, and how does it compare to Google Cloud Dataflow? Read on for a look inside one of the hottest open source projects in the world of big data.
InformationWeek: So tell us about Databricks the company. What's the mission?
Ion Stoica: When we founded Databricks, the key goal was to drive the adoption of the Apache Spark ecosystem. We've done better than expected. Today Spark is part of every major Hadoop distribution: Cloudera, Hortonworks, IBM, MapR, and Pivotal. We're even happier about the fact that Spark is now packaged in non-Hadoop distributions, such as DataStax's distribution of Apache Cassandra. It's also available on Amazon Web Services (AWS), so you can use Spark to process data in S3 (AWS Simple Storage Service).
So we've been successful in driving adoption of Spark, but more importantly, we want every user to have a great experience. To achieve that, we've partnered with several companies that are shipping Spark, and we're working closely with them to make sure that Spark customers are satisfied. Those partners are Cloudera, DataStax, and MapR, and we'll add new partners soon.
To ensure a strong application ecosystem, in February we announced an application certification program for apps that run on Apache Spark. The response has been great, and we have already certified a dozen applications. In addition, we've introduced a certification for Spark distributions, and we have five companies in that program: DataStax, Hortonworks, IBM, MapR, and Pivotal.
IW: What's the difference between partners and certified distributors?
Arsalan Tavakoli: Cloudera, MapR, and DataStax all provide Level 1 enterprise support to customers around Spark. We provide Level 2 and Level 3 support, and we train their pre-sales and post-sales support staff. In the case of distributors, like Hortonworks and Pivotal, they package certified Spark software, but they don't provide an enterprise support option as yet. Hortonworks has certified Spark on YARN, and they've introduced a technical preview before going [general availability].
[Author's Note: On July 1, SAP announced a certification of Spark on SAP Hana with Databricks through which it will distribute Spark software, but it's not yet providing Spark support.]
IW: We hear Databricks doesn't want to be a first-level support provider for software. Is that correct?
Stoica: That's correct. We're not the first line of support. That's why we partner with other companies who can distribute Spark and provide the first line of support. In fact, we do not have our own software distribution. Our strategy is quite simple: We want to build value around Apache Spark. That makes sense because, the more Spark users there are, the more customers we're going to have for our products and services.
IW: So what's the problem that Spark solves?
Stoica: If you look around today, [you'll see] companies like Google, Facebook, and Amazon that have built huge businesses by mining their data. Almost every other company is collecting data with the goal of using it to improve revenue, reduce their cost, or optimize their business in some way. However, doing that is hard. Look no farther than the fact that companies like Google, Facebook, Microsoft, and so on spend billions of dollars every year to develop data-analysis tools, systems, and big-data products.
Depending on who you are in your organization, you're tasked with one of the following: build a Hadoop cluster and manage it if you are part of the IT organization; build a data pipeline on top of Hadoop if you are a software engineer or data scientist; or use the data pipeline to turn information into value by building big-data products if you are a software engineer, data scientist, or data analyst.
Every one of these tasks is hard. Clusters are hard to set up and maintain, and it might take six to nine months. To build a data pipeline you need to stitch together a hodgepodge of tools -- MapReduce, Hive, Impala, Drill, Mahout, Giraph... When you look at this entire data pipeline, it's very complex. It requires you to integrate disparate sets of clunky tools, and even after you do that, you still have to navigate data and, even harder, develop and maintain applications. So extracting value from the data remains a struggle.
IW: So that's Apache Spark, but now you're introducing Databricks Cloud. How do the two relate to each other?
Stoica: Our goal with Databricks Cloud is to dramatically simplify data analysis and processing. In particular, we alleviate the need to set up and manage a cluster. For that, we provide a hosted solution, which makes it very easy to instantiate and manage clusters. To obviate the need to deal with a zoo of tools, we are leveraging Apache Spark, which integrates the functionality of many of the leading big data tools and systems.
To simplify data analysis, we are introducing Databricks Workplace, which includes three components: Notebooks, Dashboards, and Job Launcher. Notebooks support interactive query processing and visualization, as well as collaboration, so multiple users can do joint data exploration. Once you create one or more Notebooks, you can take the most interesting results and create and publish dashboards. Finally, the Job Launcher lets you run arbitrary Spark jobs, either periodically, based on triggers, or in production on a regular schedule. Databricks Cloud can also take inputs from other storage systems, and you can use your favorite BI tools through an ODBC connector.
[Want more on Databricks' product? Read Databricks Cloud: Next Step For Spark.]
IW: What's the timeline for general availability, and can you say anything about pricing?
Tavakoli: At this point, it's limited availability, but we'll be ramping up capacity, and we expect GA to be in the fall. As for pricing, we aren't really talking about it yet, but it will be in a tiered model to give people predictability based on usage capacity. It will start at a couple of hundred dollars per user, per month.
Figure 2:  Databricks' depiction of Databricks Cloud replacing the many components of Hadoop used in today's big-data analyses.
Databricks' depiction of Databricks Cloud replacing the many components of Hadoop used in today's big-data analyses.
IW: There are many data-processing engines and frameworks out there, but it sounds like you've tried to cover the key bases with Spark.
Stoica: We do believe that the vast majority of data-analysis jobs can be done on top of Spark. We have Spark Streaming for streaming analysis. Spark SQL is a new component for SQL where before we had Shark. We have powerful libraries for machine learning with MLLib and for Graph processing GraphX. We are also announcing Spark R to bind to the R language. This is the strength of our platform.
IW: Have you considered running on a standalone, generic clustered server platform?
Tavakoli: Spark acts as a processing and computation engine, but we have deferred the data management. We can run on multiple storage systems, including HDFS, Cassandra with support from DataStax, or Amazon S3. With Databricks Cloud, we use S3 because that's more prevalent in the cloud, but we're just as happy to work with a customer who has their data in HDFS. Hadoop handles the data management, but Spark provides the processing engine. In the on-premises world, most organizations are doing [big] data management in Hadoop clusters. We will continue to invest to make sure that Spark plays well with YARN and Hadoop clusters.
IW: How usable are Spark and Databricks Cloud to someone with SQL experience?
Tavakoli: We support SQL, Python, Java, Scala, and, very soon, R as input languages, and from there it's a single system. So think of Spark capabilities not as separate tools, but as libraries that can be called from within one system.
IW: But you still need MapReduce expertise, machine-learning expertise, SQL expertise, and so on, right?
Stoica: We think it's a better and more consistent experience. Instead of having separate schedulers, task management, and so on for each engine, in Spark the level of abstraction is much higher. It's a single execution engine, and all the libraries can share the same data. There's no data transformation required, and furthermore, the data is all in memory. The analogy might be the Microsoft tools in Office. You cut and paste from Excel, and you can bring it into PowerPoint. That's the level of integration within Spark.
IW: How would you compare Databricks Cloud and Google Cloud Dataflow? Are you on parallel tracks?
Stoica: Absolutely, but there are a few differences. One difference is that our API is open, because it's built on Apache Spark. You can build your application on top of Databricks Cloud, and then you can take your application and you can run on premises on Cloudera's Hadoop distribution.
Second, Google Cloud Dataflow is more targeted toward developers. Through our Workspace and applications like Notebooks and Dashboards, we're trying to provide a much higher level of abstraction and make it easier to use for data scientists and data analysts. A last point is that I think we provide a more complete, end-to-end data pipeline than what Google Cloud Dataflow provides because of all the analysis components we offer.
InformationWeek's June Must Reads is a compendium of our best recent coverage of big data. Find out one CIO's take on what's driving big data, key points on platform considerations, why a recent White House report on the topic has earned praise and skepticism, and much more (registration required).
About the Author(s)
You May Also Like
More Insights
Webinars
Editor's Choice





May 2, 2024
While there are plentiful options in cyber resiliency and business continuity tools and platforms, there isn’t one that can knock out everything from sudden cloud outages to prolonged ransomware attacks in a single punch. What can you do to keep the company on its feet no matter what is thrown at it? Find out in this new virtual event.
Reserve Your Seat Now